Al ROBOLAB @University of Luxembourg | N. Shojaee, B. Antico |2022
Observe une IA danser sur de la musique!
Pour cette exposition en 2022, nous avons entraîné un programme d’IA à écouter de la musique et à générer des mouvements de danse pour accompagner cette musique. Les vidéos suivantes vous montrent deux exemples de mouvements de danse générés par notre programme d’IA pour deux styles de danse différents: le ballet et le tango.
Ces vidéos montrent les résultats d’une intelligence artificielle qui a été entrainée sur 71 heures de séquences de clips de danse avec de la musique. Les poses de danse sont définies par 14 points clés (articulations des bras et des jambes, épaules, …) formant un squelette représentant les mouvements de danse. L’IA choisit une série de mouvements de danse qui correspondent le mieux à la musique, sur la base des données d’entraînement sur lesquelles le programme a appris.
Les difficultées de ce projet
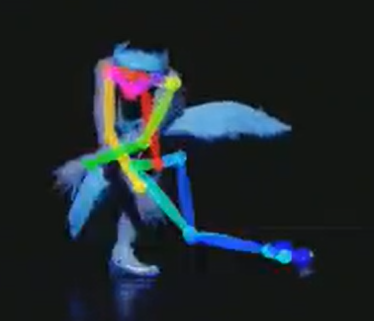
Au cours du projet, de nombreux défis ont été relevés pour permettre à l’IA de comprendre les mouvements de danse et de les adapter à la musique. En particulier pour les mouvements de danse les plus complexes, l’IA a eu du mal à faire correspondre le squelette aux mouvements de danse. Regardez la vidéo suivante, à gauche, qui montre une vidéo d’entraînement d’un danseur de ballet et les résultats de l’intelligence artificielle. Les images de droite montrent deux images de poses de danse difficiles.
La jambe gauche de la danseuse est soulevée derrière son corps et donc invisible, ce qui empêche de définir correctement le squelette.
Une pose plus complexe, comme celle présentée ci-dessus, pose des problèmes à l’IA pour relier correctement les points clés du squelette au danseur.
Notre idée pour une prochaine étape
Une idée complémentaire à ces danses automatisées était de faire danser un robot semi-humanoïde. Pepper est le premier robot semi-humanoïde social fabriqué par SoftBank Robotics, capable de reconnaître les visages et les émotions humaines de base. Pepper a été optimisé pour l’interaction humaine et est capable d’interagir avec les gens grâce à la conversation et à son écran tactile. Les caractéristiques physiques et interactives de Pepper nous ont incités à concevoir pour lui une séquence de danse classique de base et à expérimenter l’interaction homme-robot par le biais de la danse. Regardez les chorégraphies de danse utilisant le robot Pepper dans la vidéo suivante.
La vidéo ne provient pas de notre projet, mais d'une autre entreprise!